上海声通信息科技股份有限公司作为交互式人工智能市场的领导者,具有极强的技术优势和突出的产品特点。公司基于自研的融合通信及人工智能两项核心技术,打造了丰富的、高度标准化的产品模块,为客户提供高效、稳定的产品体验。公司主要的业务场景为智慧城市、智慧出行、智慧通信和智慧金融,同时公司也在积极开辟产品的其他场景以及创新应用。
论文介绍
Branchformer是由卡内基梅隆大学提出的一种结构更加灵活,可解释性更强,且可以更加灵活配置的新一代encoder结构。在ESPnet框架中,在同等参数量的情况下实验测试多个常用数据集(aishell等)结果均齐平或优于Conformer结构。其文章已被ICML2022收录,本文主要讲解其大致结构,并对其在WeNet框架中对其进行复现。
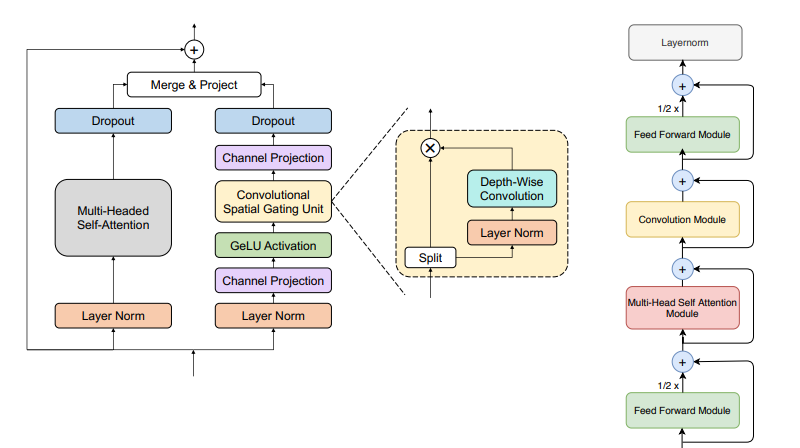
引言:自从被提出后,Conformer结构凭借其高效性被广泛的应用在包括ASR等任务的语音领域,并在多项任务保持着state-of-the-art。相对于Transformer结构,它能够更好的捕获局部与全局特征。然而,Conformer利用了一种串行的方式在每个encoder_layer将音频依次通过self-attention模块与卷积模块并传入下一层。纵然,这种方式也取得了很不错的效果,但是其可解释性可能有点迷惑。局部特征与全局特征之间的关系是怎样的?他们是怎么融合的,他们同等重要吗?还是其中的哪一种扮演着更重要的角色呢?
带着上面的问题,一种新的encoder结构Branchformer被提出了。相较于Conformer马卡龙夹心堆叠结构的结构,Branchformer做了如下改进:
-
采用了并行的双分支结构。其中分支一利用multiheaded self-attention机制提取输入序列中的全局特征,分支二则引入了cgMLP结构,意在捕获音频序列中的局部特征。
-
MLP with convolutional gating(cgMLP)模块,利用深度可分离卷积于线性门控单元的组合来学习序列中的特征表示。
-
Concat与可学习参数加权等多种特征组合方式
-
Stochastic Layer Skip,训练时通过随机丢弃encoder_layer来增强模型鲁棒性(Espnet代码中添加,论文中没有提到)
模型实现
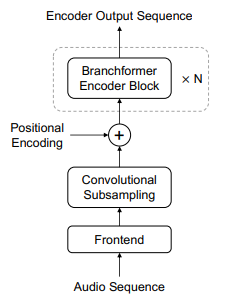
通过对论文及源代码的阅读,我们发现Branchformer与Conformer的区别主要在于其encoder_layer中对特征的提取及组合方式,而缩小后看整体的处理流程相差并不大。我们参考ESPnet中Branchformer的代码,完成了其在WeNet框架中的实现。
cgMLP模块

def forward(
self,
x: torch.Tensor,
mask: torch.Tensor,
cache: torch.Tensor = torch.zeros((0, 0, 0))
) -> Tuple[torch.Tensor, torch.Tensor]:
"""Forward cgMLP"""
xs_pad = x
# size -> linear_units
xs_pad = self.channel_proj1(xs_pad)
# linear_units -> linear_units/2
xs_pad, new_cnn_cache = self.csgu(xs_pad, cache)
# linear_units/2 -> size
xs_pad = self.channel_proj2(xs_pad)
out = xs_pad
return out, new_cnn_cache
CSGU是cgMLP中的关键,其先将输入序列按feature dimension一分为二,其中一部分会通过layer norm及depth-wise convolution,而后再与另一部分做element-wise multiplication得到输出。由于WeNet中引入了cache,我们在这里计算并更新cnn_cache。
def forward(
self,
x: torch.Tensor,
cache: torch.Tensor = torch.zeros((0, 0, 0))
) -> Tuple[torch.Tensor, torch.Tensor]:
"""Forward CSGU"""
x_r, x_g = x.chunk(2, dim=-1)
# exchange the temporal dimension and the feature dimension
x_g = x_g.transpose(1, 2) # (#batch, channels, time)
if self.lorder > 0:
if cache.size(2) == 0: # cache_t == 0
x_g = nn.functional.pad(x_g, (self.lorder, 0), 'constant', 0.0)
else:
assert cache.size(0) == x_g.size(0) # equal batch
assert cache.size(1) == x_g.size(1) # equal channel
x_g = torch.cat((cache, x_g), dim=2)
assert (x_g.size(2) > self.lorder)
new_cache = x_g[:, :, -self.lorder:]
else:
# It's better we just return None if no cache is required,
# However, for JIT export, here we just fake one tensor instead of
# None.
new_cache = torch.zeros((0, 0, 0), dtype=x_g.dtype, device=x_g.device)
x_g = x_g.transpose(1, 2)
x_g = self.norm(x_g) # (N, T, D/2)
x_g = self.conv(x_g.transpose(1, 2)).transpose(1, 2) # (N, T, D/2)
if self.linear is not None:
x_g = self.linear(x_g)
x_g = self.act(x_g)
out = x_r * x_g # (N, T, D/2)
out = self.dropout(out)
return out, new_cache
Merge Two Branches 合并分支特征
作者提出了三种不同的特征融合方法,直接concat,等权重线性融合,可学习权重融合,代码整体改动不大,仅需要注意替换numpy等模块以免影响torch.jit模型导出。
if self.merge_method == "concat":
x = x + stoch_layer_coeff * self.dropout(
self.merge_proj(torch.cat([x1, x2], dim=-1))
)
elif self.merge_method == "learned_ave":
if (
self.training
and self.attn_branch_drop_rate > 0
and torch.rand(1).item() < self.attn_branch_drop_rate
):
# Drop the attn branch
w1, w2 = torch.tensor(0.0), torch.tensor(1.0)
else:
# branch1
score1 = (self.pooling_proj1(x1).transpose(1, 2) / self.size**0.5)
score1 = score1.masked_fill(mask_pad.eq(0), -float('inf'))
score1 = torch.softmax(score1, dim=-1).masked_fill(
mask_pad.eq(0), 0.0
)
pooled1 = torch.matmul(score1, x1).squeeze(1) # (batch, size)
weight1 = self.weight_proj1(pooled1) # (batch, 1)
# branch2
score2 = (self.pooling_proj2(x2).transpose(1, 2) / self.size**0.5)
score2 = score2.masked_fill(mask_pad.eq(0), -float('inf'))
score2 = torch.softmax(score2, dim=-1).masked_fill(
mask_pad.eq(0), 0.0
)
pooled2 = torch.matmul(score2, x2).squeeze(1) # (batch, size)
weight2 = self.weight_proj2(pooled2) # (batch, 1)
# normalize weights of two branches
merge_weights = torch.softmax(
torch.cat([weight1, weight2], dim=-1), dim=-1
) # (batch, 2)
merge_weights = merge_weights.unsqueeze(-1).unsqueeze(
-1
) # (batch, 2, 1, 1)
w1, w2 = merge_weights[:, 0], merge_weights[:, 1] # (batch, 1, 1)
x = x + stoch_layer_coeff * self.dropout(
self.merge_proj(w1 * x1 + w2 * x2)
)
elif self.merge_method == "fixed_ave":
x = x + stoch_layer_coeff * self.dropout(
self.merge_proj(
(1.0 - self.cgmlp_weight) * x1 + self.cgmlp_weight * x2
)
)
else:
raise RuntimeError(f"unknown merge method: {self.merge_method}")
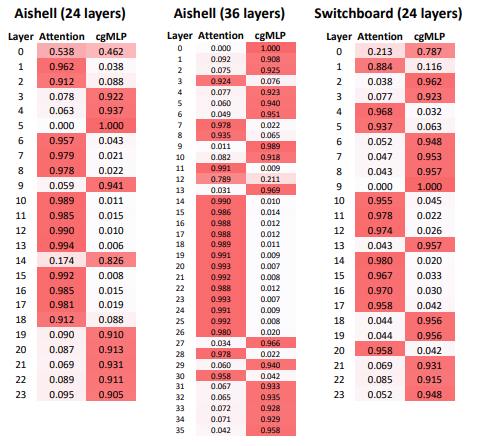
文中作者对比了不同merge操作对模型的影响,并且可视化了可学习参数在不同深度encoder_layer中的权重分布
Stochastic Layer Skip
在ESPnet代码中添加了Stochastic depth,在配置参数中启用此选项可以在训练时随机跳过某些层。从而使得Branchformer能够训练更加深的网络,在训练时随机跳过层可以加速训练且使模型更加鲁棒。
stoch_layer_coeff = 1.0
# with stochastic depth, residual connection `x + f(x)` becomes
# `x <- x + 1 / (1 - p) * f(x)` at training time.
if self.training and self.stochastic_depth_rate > 0:
skip_layer = torch.rand(1).item() < self.stochastic_depth_rate
stoch_layer_coeff = 1.0 / (1 - self.stochastic_depth_rate)
流式推理
虽然Branchformer利用俩个分支分别计算global与local特征,但在流式计算时实际上与Conformer类似,可以分别计算出atten_cache与cnn_cache做更新。方法与Conformer无异,基本可直接套用。
for i, layer in enumerate(self.encoders):
# NOTE(xcsong): Before layer.forward
# shape(att_cache[i:i + 1]) is (1, head, cache_t1, d_k * 2),
# shape(cnn_cache[i]) is (b=1, hidden-dim, cache_t2)
xs, _, new_att_cache, new_cnn_cache = layer(
xs, att_mask, pos_emb,
att_cache=att_cache[i:i + 1] if elayers > 0 else att_cache,
cnn_cache=cnn_cache[i] if cnn_cache.size(0) > 0 else cnn_cache
)
# NOTE(xcsong): After layer.forward
# shape(new_att_cache) is (1, head, attention_key_size, d_k * 2),
# shape(new_cnn_cache) is (b=1, hidden-dim, cache_t2)
r_att_cache.append(new_att_cache[:, :, next_cache_start:, :])
r_cnn_cache.append(new_cnn_cache.unsqueeze(0))
实验结果
我们在WeNet上贡献了完整的Branchformer训练方案,并针对encoder layer number,linear units 等参数在aishell数据集上做了相关实验。
| 模型配置 | attention | attention_rescore | ctc_prefix_beam_search | ctc_greedy_search |
|---|---|---|---|---|
| 24 layers + 2048 linear units | 5.12 | 4.81 | 5.28 | 5.28 |
| 24 layers + 1024 linear units | 5.33 | 4.88 | 5.41 | 5.40 |
| 12 layers + 2048 linear units | 5.37 | 5.08 | 5.69 | 5.69 |
参考资料
Branchformer:https://arxiv.org/abs/2207.02971
ESPnet:https://github.com/espnet/espnet/blob/master/espnet2/asr/encoder/branchformer_encoder.py