终于! 中文基座模型CPM-Bee开源了
# CPM-Bee
百亿参数的开源中英文双语基座大模型
✨ 模型介绍
CPM-Bee是一个完全开源、允许商用的百亿参数中英文基座模型,也是CPM-Live训练的第二个里程碑。它采用Transformer自回归架构(auto-regressive),在超万亿(trillion)高质量语料上进行预训练,拥有强大的基础能力。开发者和研究者可以在CPM-Bee基座模型的基础上在各类场景进行适配来以创建特定领域的应用模型。
-
👐 开源可商用:OpenBMB始终秉承“让大模型飞入千家万户”的开源精神,CPM-Bee基座模型将完全开源并且可商用,以推动大模型领域的发展。我们鼓励全球范围内的科研机构、企业和个人开发者在遵守开源许可协议的前提下,自由地在CPM-Bee基座模型上进行创新。
-
💫 中英双语性能优异: CPM-Bee基座模型在预训练语料上进行了严格的筛选和配比,同时在中英双语上具有亮眼表现,具体可参见评测任务和结果。
-
📖 超大规模高质量语料: CPM-Bee基座模型在超万亿语料进行训练,是开源社区内经过语料最多的模型之一。同时,我们对预训练语料进行了严格的筛选、清洗和后处理以确保质量。
-
 OpenBMB大模型系统生态支持: OpenBMB大模型系统在高性能预训练、适配、压缩、部署、工具开发了一系列工具,CPM-Bee基座模型将配套所有的工具脚本,高效支持开发者进行进阶使用。
OpenBMB大模型系统生态支持: OpenBMB大模型系统在高性能预训练、适配、压缩、部署、工具开发了一系列工具,CPM-Bee基座模型将配套所有的工具脚本,高效支持开发者进行进阶使用。 -
🔨 对话和工具使用能力: 结合OpenBMB在指令微调和工具学习的探索,我们在CPM-Bee基座模型的基础上进行微调,训练出了具有强大对话和工具使用能力的实例模型,API和内测将于近期开放。
安装
一、服务部署
1、服务器配置:
-
1)配置详情
GPU:8*3080TI服务器 (一块24G显存的卡就可以了)
CUDA:12.1
2、环境安装
cat requirements.txt
(python38) root@-NF5468M5: cat requirements.txt
torch>=1.10
bmtrain>=0.2.1
jieba
tqdm
tensorboard
numpy>=1.21.0
spacy
opendelta
为了避免cuda环境和pytorch版本的冲突,一个个进行安装。
-
1)安装pytorch,适配cuda12.1
参考:https://pytorch.org/get-started/locally/
注意:使用cuda安装比较慢,所以用pip3安装
pip3 install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu121 -
2)安装bmtrain
pip install bmtrain -
3)安装其他环境
pip install jieba tqdm tensorboard numpy spacy opendelta
3、模型下载
下载地址:https://huggingface.co/openbmb/cpm-bee-10b/tree/main
-
1)代码克隆
git clone https://github.com/OpenBMB/CPM-Bee.git -
2)下载模型 19G
下载路径: ./model下载路径,自定义即可

4、测试
-
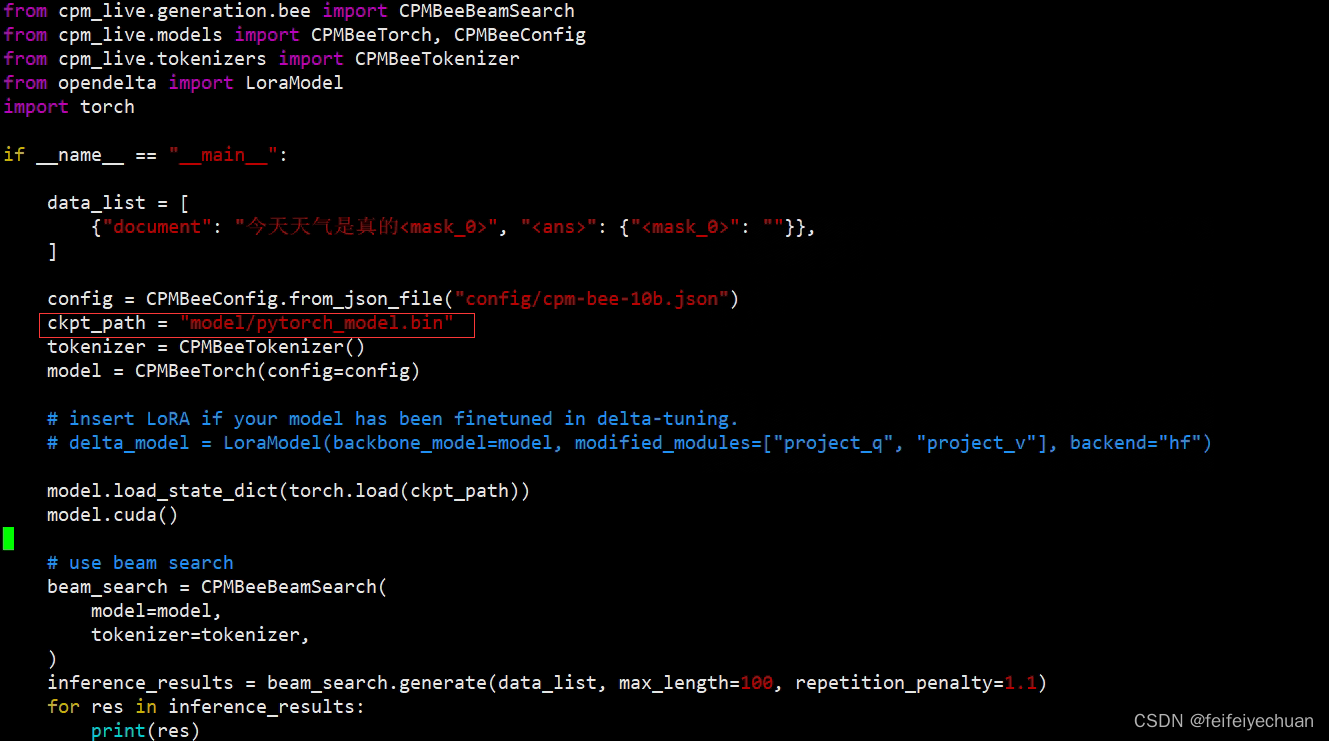
1)修改测试文件
修改
vi text_generation.py更改模型路径
-
2)测试模型
python text_generation.py
5、接口设计(Python版)
-
1)新建Flask接口
vi flask_server.pyfrom flask import Flask, request, jsonify import threading import torch from cpm_live.generation.bee import CPMBeeBeamSearch from cpm_live.models import CPMBeeTorch, CPMBeeConfig from cpm_live.tokenizers import CPMBeeTokenizer from opendelta import LoraModel from flask_cors import CORS import os os.environ["CUDA_VISIBLE_DEVICES"] = '6' app = Flask(__name__) CORS(app) # 加载模型 config = CPMBeeConfig.from_json_file("config/cpm-bee-10b.json") ckpt_path = "model/pytorch_model.bin" tokenizer = CPMBeeTokenizer() model = CPMBeeTorch(config=config) model.load_state_dict(torch.load(ckpt_path)) model.cuda() beam_search = CPMBeeBeamSearch( model=model, tokenizer=tokenizer, ) # 创建线程锁和计数器 lock = threading.Lock() counter = 0 MAX_CONCURRENT_REQUESTS = 5 # 最大并发请求数 @app.route('/cpmbee/conversation', methods=['POST']) def conversation(): global counter # 请求过载,返回提示信息 if counter >= MAX_CONCURRENT_REQUESTS: return jsonify({'message': '请稍等再试'}) # 获取线程锁 with lock: counter += 1 try: # 接收 POST 请求的数据 question = request.json['question'] inference_results = beam_search.generate([ {'question': question, "<ans>": ""} ], max_length=100, repetition_penalty=1.1) print('inference_results:', type(inference_results), inference_results) result = inference_results[0]["<ans>"] print('result:', type(result), result) # 返回结果 response = {'result': result} return jsonify(response) finally: # 释放线程锁并减少计数器 with lock: counter -= 1 @app.route('/cpmbee/select', methods=['POST']) def select(): global counter # 请求过载,返回提示信息 if counter >= MAX_CONCURRENT_REQUESTS: return jsonify({'message': '请稍等再试'}) # 获取线程锁 with lock: counter += 1 try: # 接收 POST 请求的数据 print(request.json) description = request.json['description'] options = request.json['options'] options_index2option = {'<option_%s>' % str(index): str(option) for index, option in enumerate(options)} question = request.json['question'] inference_results = beam_search.generate([ {'input': description, 'options': options_index2option, 'question': question, "<ans>": ""} ], max_length=100, repetition_penalty=1.1) option_result = inference_results[0]["<ans>"] result = options_index2option.get(option_result, option_result) # 返回结果 response = {'result': result} return jsonify(response) finally: # 释放线程锁并减少计数器 with lock: counter -= 1 if __name__ == '__main__': print("Flask 服务器已启动") app.run(host='0.0.0.0', port=8000)在上述代码中,我们通过
from flask_cors import CORS导入了CORS类,并在 Flask 应用程序中调用了CORS(app)。这样就启用了默认的 CORS 配置,允许所有来源跨域访问。未避免显存异常,在上述代码中,通过创建一个线程锁
lock和一个计数器counter来控制并发请求的数量。如果请求超过了MAX_CONCURRENT_REQUESTS的限制,即达到了最大并发请求数,服务器将返回提示信息"请稍等再试"。 -
2)启动接口
python flask_server.py -
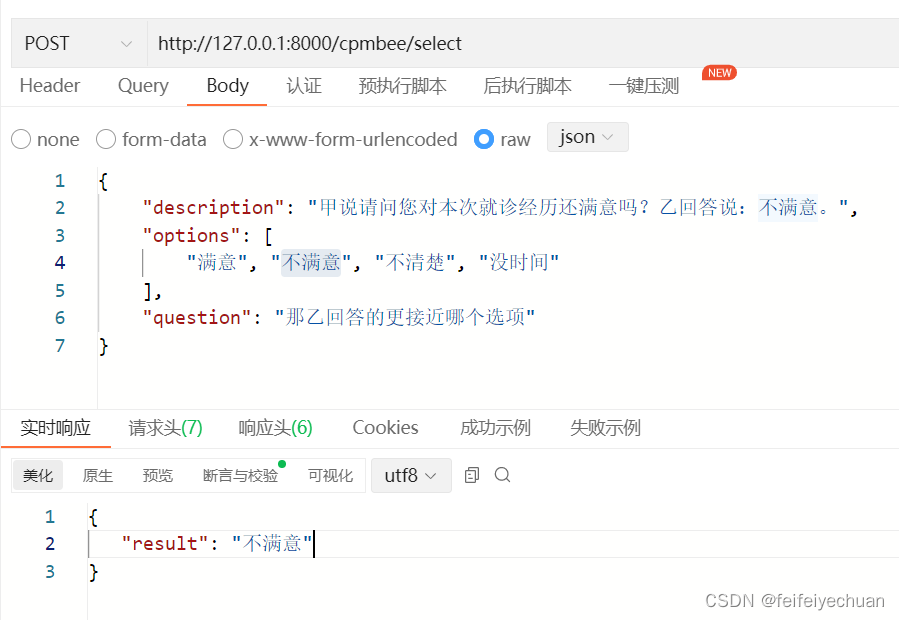
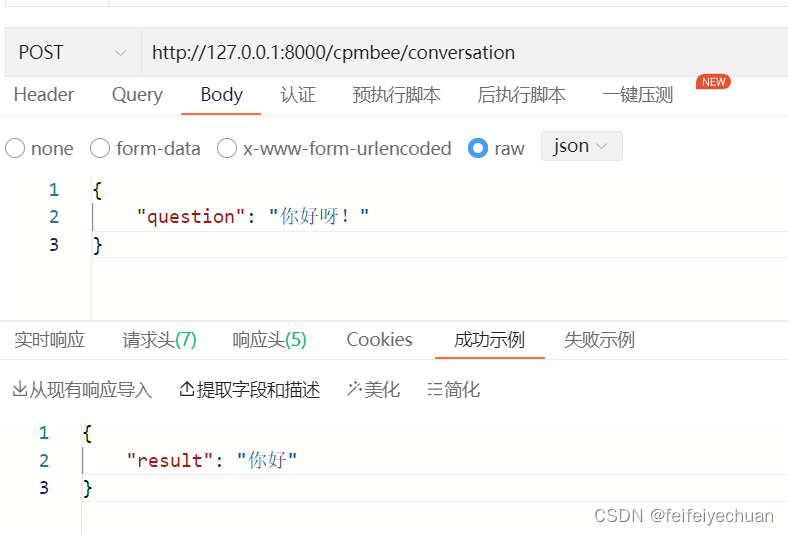
3)接口测试
-
选择题测试
-
Chat测试
-
二、聊天窗口(前后端)