欢迎关注「全栈工程师修炼指南」公众号
点击 👇 下方卡片 即可关注我哟!
设为「星标⭐」每天带你 基础入门 到 进阶实践 再到 放弃学习!
“ 花开堪折直须折,莫待无花空折枝。 ”
作者主页:[ https://www.weiyigeek.top ]
博客:[ https://blog.weiyigeek.top ]
作者安全运维学习答疑交流群:请关注公众号回复【学习交流群】
0x00 快速了解
EasyOCR 介绍
Q: 什么是 EasyOCR ?
描述: EasyOCR 是一个用于从图像中提取文本的 python 模块, 它是一种通用的 OCR,既可以读取自然场景文本,也可以读取文档中的密集文本。目前支持 80 多种语言和所有流行的书写脚本,包括:拉丁文、中文、阿拉伯文、梵文、西里尔文等。
Q: 使用 EasyOCR 可以干什么?
描述: EasyOCR 支持两种方式运行一种是常用的CPU,而另外一种是需要GPU支持并且需安装CUDA环境, 我们使用其可以进行图片中语言文字识别, 例如小程序里图片识别、车辆车牌识别(
即车债管理系统)。

Tips: 在其官网有demo演示,我们可以使用其进行简单图片ocr识别,地址为https://www.jaided.ai/easyocr/ 或者 https://huggingface.co/spaces/tomofi/EasyOCR
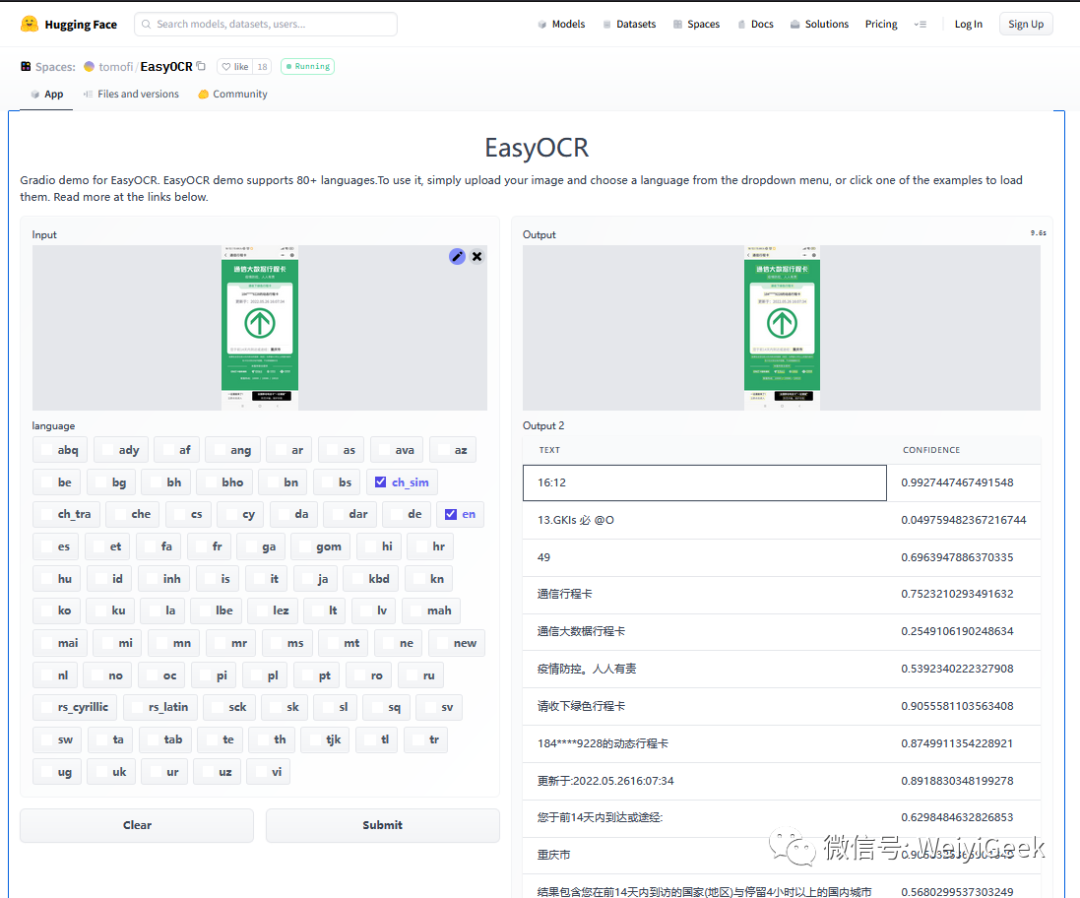
EasyOCR Framework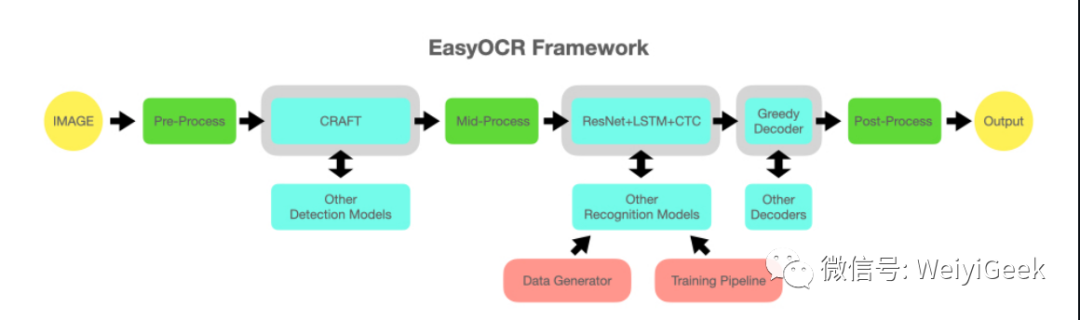
温馨提示: 图中 灰色插槽是可更换的浅蓝色模块的占位符,我们可以重构代码以支持可交换的检测和识别算法 api
EasyOCR 参考来源
官网地址: https://www.jaided.ai/easyocr/
项目地址: https://github.com/JaidedAI/EasyOCR
作者在疫情期间,使用该开源项目开发的行程码、健康码项目(供大家参考学习):https://github.com/WeiyiGeek/SecOpsDev/tree/master/Project/Python/EasyOCR/Travelcodeocr
文档原文地址: https://www.bilibili.com/read/cv16911816
实践视频地址: https://www.bilibili.com/video/BV1nY4y1x7JG
温馨提示: 该项目基于来自多篇论文和开源存储库的研究和代码,所有深度学习执行都基于 Pytorch ,识别模型是 CRNN 它由 3 个主要部分组成:特征提取(我们目前使用 Resnet )和 VGG、序列标记( LSTM )和解码( CTC )。❤️
0x01 安装部署
环境依赖
环境依赖
Python 建议 3.8 x64 以上版本 (原本我的环境是 Python 3.7 安装时各种稀奇古怪的错误都出来,不得已abandon放弃)
easyocr 包 -> 依赖 torch 、torchvision 第三方包
注意事项:
Note 1.本章是基于 cpu 与 GPU 下使用 EasyOCR, 如果你需要使用 GPU 跑, 那么请你安装相应的CUDA环境。
$ nvidia-smi -l
Fri May 27 14:57:57 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 465.19.01 Driver Version: 465.19.01 CUDA Version: 11.3 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA Tesla V1... Off | 00000000:1B:00.0 Off | 0 |
| N/A 41C P0 36W / 250W | 0MiB / 32510MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+Note 2.最好在Python 3.8 x64 位系统上安装使用 easyocr , 非常注意其不支持32位的python。
Note 3.对于 Windows,请先按照 https://pytorch.org 的官方说明安装 torch 和 torchvision。在 pytorch 网站上,请务必选择您拥有的正确 CUDA 版本。如果您打算仅在 CPU 模式下运行,请选择 CUDA = None。
环境安装
描述: 此处我们使用 pip 安装 easyocr 使用以及通过官方提供的Dockerfile。
pip 方式
对于最新的稳定版本:
pip install easyocr -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com对于最新的开发版本:
pip install git+git://github.com/jaidedai/easyocr.gitDockerfile
描述: 由于国内网络环境因素, 此处我将官方提供的Dockerfile稍作更改。
$ cd /opt/images/easyocr && git clone https://github.com/JaidedAI/EasyOCR.git --depth=1
$ ls
Dockerfile EasyOCR
$ cat Dockerfile
# pytorch OS is Ubuntu 18.04
FROM pytorch/pytorch
LABEL DESC="EasyOCR Enviroment Build with Containerd Images"
ARG service_home="/home/EasyOCR"
# Enviroment && Software
RUN sed -i -e "s#archive.ubuntu.com#mirrors.aliyun.com#g" -e "s#security.ubuntu.com#mirrors.aliyun.com#g" /etc/apt/sources.list && \
apt-get update -y && \
apt-get install -y \
libglib2.0-0 \
libsm6 \
libxext6 \
libxrender-dev \
libgl1-mesa-dev \
git \
vim \
# cleanup
&& apt-get autoremove -y \
&& apt-get clean -y \
&& rm -rf /var/lib/apt/lists
# COPY EasyOCR is Github(https://github.com/JaidedAI/EasyOCR.git)
COPY ./EasyOCR "$service_home"
# Build
RUN cd "$service_home" \
&& pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/ \
&& python setup.py build_ext --inplace -j 4 \
&& python -m pip install -e .环境验证
# Windows 环境
pip freeze | findstr "easyocr"
easyocr @ file:///E:/%E8%BF%85%E9%9B%B7%E4%B8%8B%E8%BD%BD/easyocr-1.4.2-py3-none-any.whl
# Linux & 容器环境
$ pip freeze | grep "EasyOCR"
-e git+https://github.com/JaidedAI/EasyOCR.git@7a685cb8c4ba14f2bc246f89c213f1a56bbc2107#egg=easyocr
# python 命令行中使用
>>> from pprint import pprint # 方便格式化输出
>>> import easyocr
>>> reader = easyocr.Reader(['ch_sim','en'])
CUDA not available - defaulting to CPU. Note: This module is much faster with a GPU.
>>> result = reader.readtext('00e336dbde464c809ef1f6ea568d4621.png')
>>> pprint(result)
[([[354, 46], [444, 46], [444, 76], [354, 76]], '中国移动', 0.981803297996521),
([[477, 55], [499, 55], [499, 75], [477, 75]], '46', 0.3972922105840435),
([[533, 55], [555, 55], [555, 75], [533, 75]], '5G', 0.5360637875500641),
([[354, 76], [474, 76], [474, 104], [354, 104]],
'中国移动四 ',
0.25950584649873865),
([[489, 57], [625, 57], [625, 95], [489, 95]],
'GMl s @',
0.011500043801327683),
([[693, 55], [801, 55], [801, 95], [693, 95]], 'Q92%', 0.022083675488829613),
([[864, 60], [950, 60], [950, 92], [864, 92]], '09:03', 0.9793587315696877),
([[884, 158], [938, 158], [938, 214], [884, 214]], '@', 0.29484160211053734),
([[123, 298], [592, 298], [592, 361], [123, 361]],
'通信行程卡提供服务>',
0.6739866899213806),
([[115, 429], [384, 429], [384, 497], [115, 497]],
'通信行程卡',
0.9159307714297187),
([[153, 596], [848, 596], [848, 704], [153, 704]],
'通信大数据行程卡',
0.2522292283860262),
................................
([[663, 2129], [793, 2129], [793, 2173], [663, 2173]],
'保护你我',
0.9819014668464661)]
# 设置 --detail=0 输出更简单
>>> result = reader.readtext('00e336dbde464c809ef1f6ea568d4621.png', detail = 0)使用说明
Note 1.在使
easyocr.Reader(['ch_sim','en'])于将模型加载到内存中(可能会耗费一些时间), 并且我们需要设定默认阅读的语言列表, 可以同时使用多种语言,但并非所有语言都可以一起使用, 而通常会采用英语与其他语言联合。
偷偷的告诉你哟?【极客全栈修炼】微信小程序已经上线了,
可直接在微信里面直接浏览博主博客了哟,后续将上线更多有趣的小工具。
下面列举出可用语言及其语言对应列表 (https://www.jaided.ai/easyocr/) :
# 对于我们来说常用语言如下:
# Language Code Name
Simplified Chinese ch_sim
Traditional Chinese ch_tra
English en
温馨提示: 所选语言的模型权重将自动下载,或者您可以从模型中心 并将它们放在~/.EasyOCR/model文件夹中
Note 2.如果
--gpu=True设置为True, 而机器又没有GPU支持的化将默认采用 CPU ,所以通常你会看到如下提示:
# 如果您没有 GPU,或者您的 GPU 内存不足,您可以通过添加 gpu=False.
CUDA not available - defaulting to CPU. Note: This module is much faster with a GPU.Note 3.在reader.readtext('参数值')函数中的参数值,可以是图片路径、也可是图像文件字节或者 OpenCV 图像对象(numpy 数组)以及互联网上图像的URL 等几种方式.
# 图像路径
reader.readtext('chinese.jpg')
# 图像URL
reader.readtext('https://www.weiyigeek.top/wechat.jpg')
# 图形字节
with open("chinese_tra.jpg", "rb") as f:
img = f.read()
result = reader.readtext(img)
# 图像作为 numpy 数组(来自 opencv)传递
img = cv2.imread('chinese_tra.jpg')
result = reader.readtext(img)Note 3.从上面结果可以看出输出结果将采用列表格式,每个项目分别代表一个
边界框(四个点)、检测到的文本和可信度。
([[347, 844], [653, 844], [653, 892], [347, 892]], # 边界 1 --> 2 -> 3 -> 4
'请收下绿色行程卡', # 文本
0.9120484515458063), # 可信度Note 4.我们也可以在命令行中直接调用easyocr。
# 语法示例:
usage: easyocr [-h] -l LANG [LANG ...] [--gpu {True,False}] [--model_storage_directory MODEL_STORAGE_DIRECTORY]
[--user_network_directory USER_NETWORK_DIRECTORY] [--recog_network RECOG_NETWORK]
[--download_enabled {True,False}] [--detector {True,False}] [--recognizer {True,False}]
[--verbose {True,False}] [--quantize {True,False}] -f FILE
[--decoder {greedy,beamsearch,wordbeamsearch}] [--beamWidth BEAMWIDTH] [--batch_size BATCH_SIZE]
[--workers WORKERS] [--allowlist ALLOWLIST] [--blocklist BLOCKLIST] [--detail {0,1}]
[--rotation_info ROTATION_INFO] [--paragraph {True,False}] [--min_size MIN_SIZE]
[--contrast_ths CONTRAST_THS] [--adjust_contrast ADJUST_CONTRAST] [--text_threshold TEXT_THRESHOLD]
[--low_text LOW_TEXT] [--link_threshold LINK_THRESHOLD] [--canvas_size CANVAS_SIZE]
[--mag_ratio MAG_RATIO] [--slope_ths SLOPE_THS] [--ycenter_ths YCENTER_THS] [--height_ths HEIGHT_THS]
[--width_ths WIDTH_THS] [--y_ths Y_THS] [--x_ths X_THS] [--add_margin ADD_MARGIN]
# 案例:
$ easyocr -l ch_sim en -f chinese.jpg --detail=1 --gpu=False
$ easyocr -l ch_sim en -f .\0a1e948e90964d42b435d63c9f0aa268.png --detail=0 --gpu=True
# CUDA not available - defaulting to CPU. Note: This module is much faster with a GPU.
....
请收下绿色行程卡
191****8499的动态行程卡
更新于:2022.05.2510:49:21
您于前14夭内到达或途经: 重庆市
结果包含您在前14天内到访的国家(地区)与停留4小时以上的国内城市
.....方法参数
描述: 官方提供的包的模块方法以及参数说明, 参考地址 ( https://www.jaided.ai/easyocr/documentation/ )
1.EasyOCR 的基类
easyocr.Reader(['ch_sim','en'], gpu=False, model_storage_directory="~/.EasyOCR/.",download_enabled=True, user_network_directory="~/.EasyOCR/user_network",recog_network="recog_network",detector=True,recognizer=True)
# download_enabled :如果 EasyOCR 无法找到模型文件,则启用下载
# model_storage_directory: 模型数据目录的路径
# user_network_directory: 用户定义识别网络的路径
# detector : 加载检测模型到内存中
# recognizer : 加载识别模型到内存中2.Reader 对象的主要方法, 有 4 组参数:General、Contrast、Text Detection 和 Bounding Box Merging, 其返回值为列表形式。
亲,文章就要看完了,不关注一下【全栈工程师修炼指南】作者吗?

reader.readtext(
'chinese.jpg',image,decoder='greedy',beamWidth=5,batch_size=1,workers=0,allowlist="ch_sim",blocklist="ch_tra",detail=1,paragraph=False,min_size=10,rotation_info=[90, 180 ,270],
contrast_ths = 0.1, adjust_contrast = 0.5,
text_threshold = 0.7, low_text = 0.4,link_threshold = 0.4, canvas_size = 2560, mag_ratio = 1,
slope_ths = 0.1, ycenter_ths = 0.5, height_ths = 0.5, width_ths = 0.5, add_margin = 0.1, x_ths = 1.0, y_ths = 0.5
)
# Parameters 1: General
--batch_size : 当其值大于 1 时将使 EasyOCR 更快,但使用更多内存。
--allowlist : 强制 EasyOCR 仅识别字符子集。对特定问题有用(例如车牌等)
--detail : 将此设置为 0 以进行简单输出.
--paragraph :将结果合并到段落中
--min_size: 过滤小于像素最小值的文本框
--rotation_info:允许 EasyOCR 旋转每个文本框并返回具有最高置信度分数的文本框。例如,对所有可能的文本方向尝试 [90, 180 ,270]。
# Parameters 2: Contrast
--contrast_ths : 对比度低于此值的文本框将被传入模型 2 次,首先是原始图像,其次是对比度调整为“adjust_contrast”值,结果将返回具有更高置信度的那个。
--adjust_contrast : 低对比度文本框的目标对比度级别
# Parameters 3: Text Detection (from CRAFT)
--text_threshold: 文本置信度阈值
--link_threshold: 链接置信度阈值
--canvas_size: 最大图像尺寸,大于此值的图像将被缩小。
--mag_ratio: 图像放大率
# Parameters 4: Bounding Box Merging
height_ths (float, default = 0.5) - 盒子高度的最大差异,不应合并文本大小差异很大的框。
width_ths (float, default = 0.5) - 合并框的最大水平距离。
x_ths (float, default = 1.0) - 当段落 = True 时合并文本框的最大水平距离。
y_ths (float, default = 0.5) - 当段落 = True 时合并文本框的最大垂直距离。3.detect method, 检测文本框的方法。
Parameters
image (string, numpy array, byte) - Input image
min_size (int, default = 10) - Filter text box smaller than minimum value in pixel
text_threshold (float, default = 0.7) - Text confidence threshold
low_text (float, default = 0.4) - Text low-bound score
link_threshold (float, default = 0.4) - Link confidence threshold
canvas_size (int, default = 2560) - Maximum image size. Image bigger than this value will be resized down.
mag_ratio (float, default = 1) - Image magnification ratio
slope_ths (float, default = 0.1) - Maximum slope (delta y/delta x) to considered merging. Low value means tiled boxes will not be merged.
ycenter_ths (float, default = 0.5) - Maximum shift in y direction. Boxes with different level should not be merged.
height_ths (float, default = 0.5) - Maximum different in box height. Boxes with very different text size should not be merged.
width_ths (float, default = 0.5) - Maximum horizontal distance to merge boxes.
add_margin (float, default = 0.1) - Extend bounding boxes in all direction by certain value. This is important for language with complex script (E.g. Thai).
optimal_num_chars (int, default = None) - If specified, bounding boxes with estimated number of characters near this value are returned first.
Return horizontal_list, free_list - horizontal_list is a list of regtangular text boxes. The format is [x_min, x_max, y_min, y_max]. free_list is a list of free-form text boxes. The format is [[x1,y1],[x2,y2],[x3,y3],[x4,y4]].4.recognize method, 从文本框中识别字符的方法,如果未给出 Horizontal_list 和 free_list,它将整个图像视为一个文本框。
Parameters
image (string, numpy array, byte) - Input image
horizontal_list (list, default=None) - see format from output of detect method
free_list (list, default=None) - see format from output of detect method
decoder (string, default = 'greedy') - options are 'greedy', 'beamsearch' and 'wordbeamsearch'.
beamWidth (int, default = 5) - How many beam to keep when decoder = 'beamsearch' or 'wordbeamsearch'
batch_size (int, default = 1) - batch_size>1 will make EasyOCR faster but use more memory
workers (int, default = 0) - Number thread used in of dataloader
allowlist (string) - Force EasyOCR to recognize only subset of characters. Useful for specific problem (E.g. license plate, etc.)
blocklist (string) - Block subset of character. This argument will be ignored if allowlist is given.
detail (int, default = 1) - Set this to 0 for simple output
paragraph (bool, default = False) - Combine result into paragraph
contrast_ths (float, default = 0.1) - Text box with contrast lower than this value will be passed into model 2 times. First is with original image and second with contrast adjusted to 'adjust_contrast' value. The one with more confident level will be returned as a result.
adjust_contrast (float, default = 0.5) - target contrast level for low contrast text box
Return list of results更多详细信息及示例,请参照此项目的Github主页。
本文至此完毕,更多技术文章,尽情等待下篇好文!
原文地址: https://blog.weiyigeek.top/2022/5-8-658.html
如果此篇文章对你有帮助,请你将它分享给更多的人!

 学习书籍推荐 往期发布文章
学习书籍推荐 往期发布文章 
公众号回复【0008】获取【Ubuntu22.04安装与加固建脚本】
公众号回复【10001】获取【WinServer安全加固脚本】
公众号回复【0011】获取【k8S二进制安装部署教程】
公众号回复【0014】获取【Nginx学习之路汇总】
公众号回复【0015】获取【Jenkins学习之路汇总】
热文推荐
开发技能 | 如何在 Github 上给开源项目提交 PR?
开源项目 | ChatGPT-Next-Web私人ChatGPT网页应用一键免费部署
开源项目 | DB-GPT 来了,兼职奶爸搞了个数据库创新AI工具!
工具推荐 | 利用开源工具查看MobaXterm远程终端工具存储的Session账号密码信息
DataX开源项目异构数据源间数据同步基础介绍与快速入门(1)
欢迎长按(扫描)二维码 ,获取更多渠道哟!

欢迎关注 【全栈工程师修炼指南】(^U^)ノ~YO
== 全栈工程师修炼指南 ==
微信沟通交流: weiyigeeker
关注回复【学习交流群】即可加入【安全运维沟通交流小群】
温馨提示: 由于作者水平有限,本章错漏缺点在所难免,希望读者批评指正,若有问题或建议请在文章末尾留下您宝贵的经验知识,或联系邮箱地址
master@weiyigeek.top 或 关注公众号 [全栈工程师修炼指南] 留言。
[全栈工程师修炼指南] 关注 企业运维实践、网络安全、系统运维、应用开发、物联网实战、全栈文章,尽在博客站点,谢谢支持!
点个【 赞 + 在 】看吧!
点击【"阅读原文"】获取更多有趣的知识!

![[Python图像处理] 基于离散余弦变换的安全扩频数字水印](https://img-blog.csdnimg.cn/4e9777ab479b46a2b6ee5393b5a78be8.png#pic_center)