论文笔记--Baichuan 2: Open Large-scale Language Models
- 1. 文章简介
- 2. 文章概括
- 3 文章重点技术
- 3.1 预训练
- 3.1.1 预训练数据
- 3.1.2 模型架构
- 3.2 对齐
- 3.2.1 SFT
- 3.2.2 Reward Model(RM)
- 3.2.3 PPO
- 3.3 安全性
- 4. 文章亮点
- 5. 原文传送门
1. 文章简介
- 标题:Baichuan 2: Open Large-scale Language Models
- 作者:Aiyuan Yang et al.
- 日期:2023
- 期刊:arxiv preprint
2. 文章概括
文章提出了百川2开源大模型,在MMLU、GSM8K等benchmarks上超过了现有的开源模型表现,特别地,百川2在医疗、法律等垂域上表现亮眼。百川2模型包括Baichuan 2-7B 和Baichuan 2-13B 和两个不同大小模型,可以供不同需求、不同预算的研究使用,两个模型的区别如下表所示。
 百川1VS2" />
百川1VS2" />
3 文章重点技术
3.1 预训练
3.1.1 预训练数据
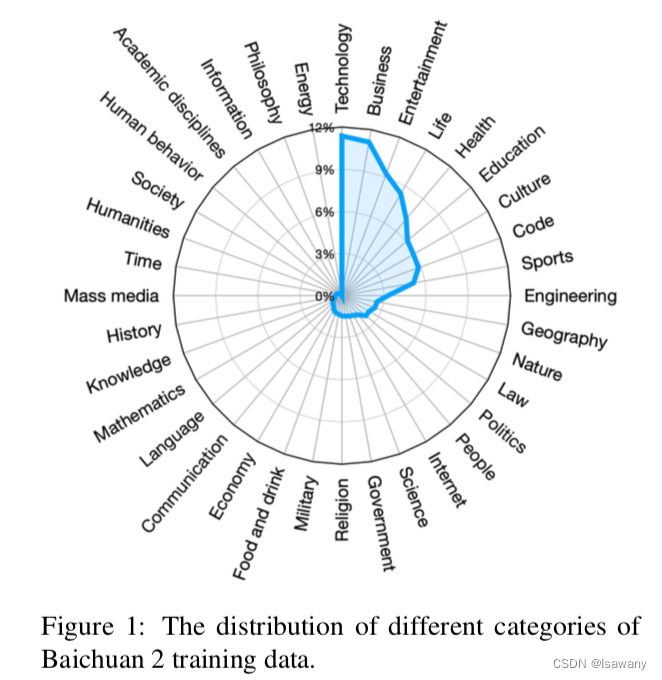
百川2尝试去提高数据的规模和代表性,为此,文章从网页、数据、研究论文、代码等不同来源构建尽可能丰富的预训练数据。下图为百川2的预训练数据分布情况
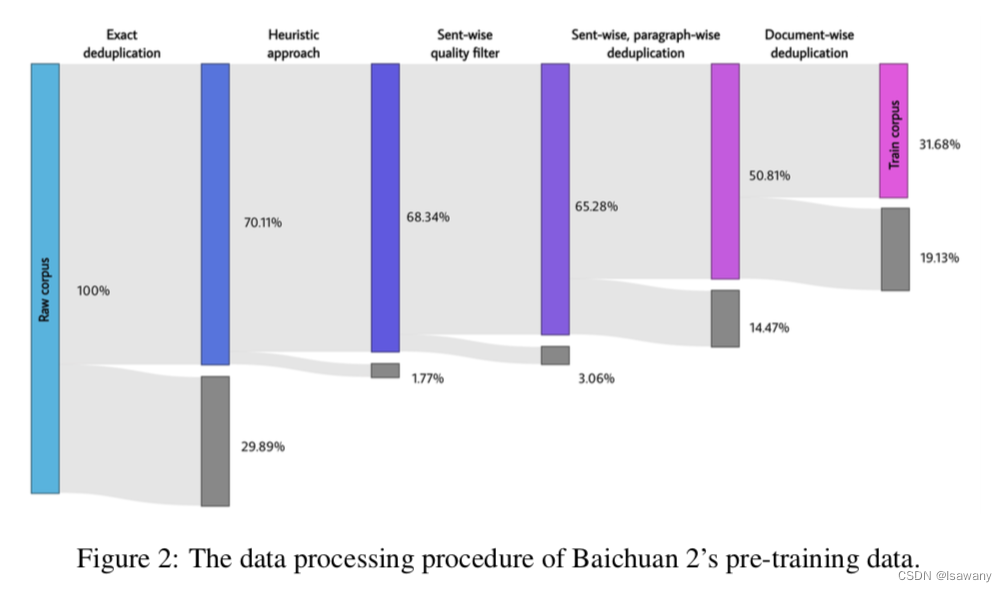
百川2希望模型可以接收尽可能高质量的数据集,为此,文章构建了高效的聚类和去重系统。如下图所示,百川2的数据处理程序分为:
- Exact deduplication:完全相同的重复数据剔除
- Heuristic approach:一些启发式的算法(文章并没有提到具体方法)
- Sent-wise quality filter:句子级别的质量过滤(maybe 过滤一些广告、tag之类的,然后再对过滤后的句子、段落去重一遍)
- Sent-wise, paragraph-wise deduplication:句子、段落级别的去重
- Document deduplication:文档级别的去重
3.1.2 模型架构
- 分词器:为了构建一个大小合适且压缩率高的分词器,文章将词表大小从百川1的64000扩充到125695。分词方法为BPE。特别地,为了更好地处理数字,百川2将数字分隔为单个的digit;为了更高地处理代码,百川2在分词器中增加了空格tokens(单个空格、多个空格分别为一个token?)
- 位置编码:百川2选择采用AliBi编码,该方法相比于RoPE编码方法表现更好。
- 激活函数:百川2使用SwiGLU作为激活函数。SwiGLU是当下一些LLMs(PALM,LLaMA等)倾向选择的一种激活函数。由于SwiGLU相当于两个线性变换(其中一个加了Swi函数)的乘积,前馈层SwiFFN包含了三个参数矩阵 ( S w i s h ( x W 1 ) × x V ) W 2 (Swish(xW_1)\times xV) W_2 (Swish(xW1)×xV)W2,为了保持相同的计算量,我们将隐藏层的尺寸从4倍隐藏层大小缩减到8/3倍隐藏层大小(缩减到原来的2/3,这样三个参数的计算量为2/3*3=2,基本和原来2个矩阵的计算量持平),再近似到128的倍数。
- Optimization:文章采用AdamW为优化器
- NormHead:文章做了数值实验发现通过使用NormHead,即正则output层(heads),训练动态过程可以更加稳定,此外文章发现语义信息主要由cosine相似度 < a , b > ∥ a ∥ 2 ∥ b ∥ 2 \frac {<a,b>}{\Vert a\Vert_2 \Vert b\Vert_2} ∥a∥2∥b∥2<a,b>进行度量,但线性层是通过计算点积 < a , b > <a,b> <a,b>进行计算的,两者之间相差了 a , b a, b a,b的L2范数,从而通过对输出层进行L2正则,我们可以有效地减轻L2距离对语义信息的影响。
- Max-z loss:文章发现训练过程中,LLMs的logits可能变得非常大,而softmax很容易被这些非常大的logits所影响。为此,一些研究选择采用惩罚项来对太大的logits进行惩罚,比如repetition penalty,但这样可能会扭曲最后生成的概率。文章类似PALM,增加一项max-z loss来对logits进行正则: L m a x − z = 2 e − 4 ∗ z 2 \mathcal{L}_{max-z} = 2e^{-4} * z^2 Lmax−z=2e−4∗z2,其中 z z z表示logits的最大值,即logits最大值越大,损失 L = L 0 + L m a x − z \mathcal{L} = \mathcal{L_0} + \mathcal{L}_{max-z} L=L0+Lmax−z越大,从而起到对太大的logits的惩罚作用
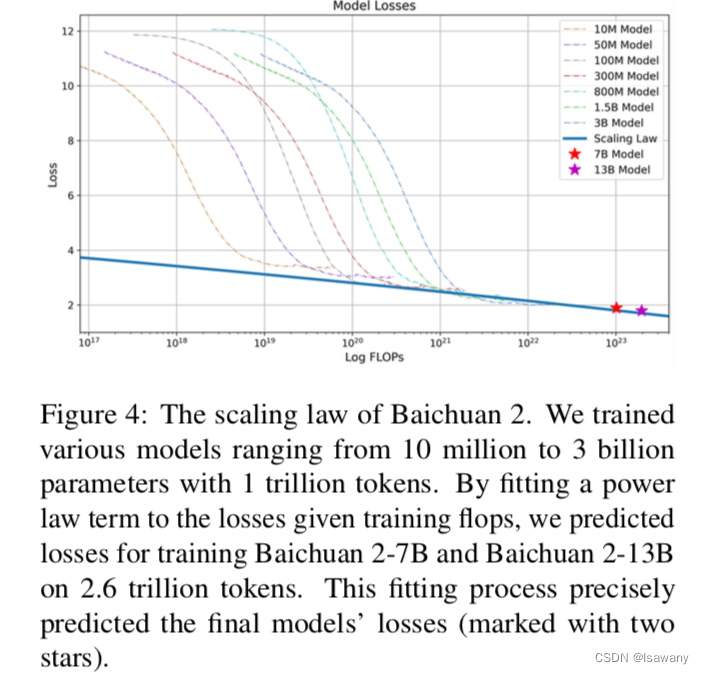
- Scaling Laws:当数据规模、模型大小或者两者增加时,模型的error会降低,这就是大名鼎鼎的Scaling law。文章通过训练从10M到3B的不同代奥的模型,得到了拟合比较好的Scaling Law曲线,且该曲线可以比较精准地预测参数量为7B/13B的error:
3.2 对齐
3.2.1 SFT
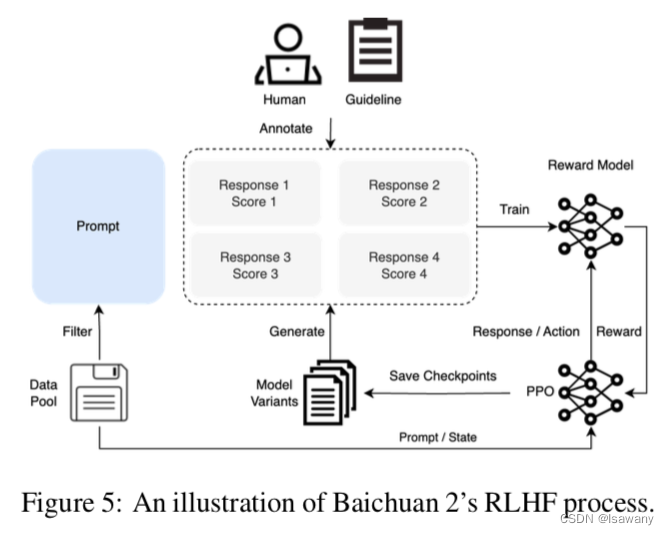
在SFT阶段,百川2请人类标注员对不同来源的prompts进行标注,每个prompt 被标记为是否有帮助、是否无害,标注原则和Claude类似。文章收集了100k个SFT数据样本,并将这些样本在base model上进行训练,然后通过RLHF方法进一步提升结果:
3.2.2 Reward Model(RM)
文章对所有的prompts构建了三层的分类系统:6个主要的类别,第二层为30个二级类别,第三层为200个三级类别。我们希望reward model训练的prompts尽可能覆盖每个类别,且每个类别的prompts尽可能多样。
给定prompt,首先通过百川2不同size和不同阶段的模型产生尽可能不同的回答。这些回答被打分,然后用于reward model的训练。
3.2.3 PPO
得到RM之后,我们采用PPO策略训练语言模型,文章采用4个模型:actor model)用于生成不同的回答,reference model(用于计算KL惩罚),reward model(提供reward),critic model(学习每个token的value)
整个RLHF的过程如下图:
3.3 安全性
随着LLMs的发展,大模型的安全性问题越来越受到学术界和工业界的重视。为了提高百川2的安全性,文章在预训练阶段设计了一系列规则和模型确预训练数据的安全,此外,文章精心选择了中英双语攻击7百万高质量网页,在预训练数据上提升了这些网页的采样概率。
在对齐阶段,文章设计了6种不同形式的攻击和100+安全分类,来自传统物联网安全的专家组生成200K的攻击attacks,然后通过一种监督采样方法,我们使用这些数据生成不同安全level的回答。在RL最优化结算,我们通过DPO方法提升具体问题上的表现,此外RM模型也会将helpful和harmless目标结合考虑来增强模型的安全性和帮助性。
4. 文章亮点
文章提出了百川2-7B/13B开源大模型,模型在多个benchmarks上表现突出,在大部分测试的中文benchmarks上达到SOTA表现,且在医疗、法律等广泛应用的垂域上有显著的提升。
5. 原文传送门
Baichuan 2: Open Large-scale Language Models