拓展阅读
敏感词工具实现思路
DFA 算法讲解
敏感词库优化流程
java 如何实现开箱即用的敏感词控台服务?
各大平台连敏感词库都没有的吗?
v0.10.0-脏词分类标签初步支持
v0.11.0-敏感词新特性:忽略无意义的字符,词标签字典
v0.12.0-敏感词/脏词词标签能力进一步增强
背景
想实现一个基于敏感词库的敏感词工具。
遍历匹配
发现如果是逐个字符遍历的话,效率实在是太低。
这里我首先想到了两种算法:
KMP 算法
BF 暴力匹配算法
当然单纯只是匹配,其实性能依然非常的低。
正则表达式
当然还有一种方式就是基于正则表达式,个人感觉这种性能也比较差。
正则表达式
直接查了下资料,可以使用 DFA 算法来解决这个问题。
DFA 算法
在实现文字过滤的算法中,DFA是比较好的实现算法。
DFA 即 Deterministic Finite Automaton,也就是确定有穷自动机,它是是通过event和当前的state得到下一个state,即event+state=nextstate。
流程图示
下图展示了其状态的转换

在这幅图中大写字母(S、U、V、Q)都是状态,小写字母a、b为动作。
通过上图我们可以看到如下关系
a b b
S -----> U S -----> V U -----> V
ps: 说到有穷状态机,又让我想起了正则表达式。感觉冥冥之中,这些东西还是相通的。
在实现敏感词过滤的算法中,我们必须要减少运算,而DFA在DFA算法中几乎没有什么计算,有的只是状态的转换。
开源地址
为了便于大家学习,项目开源地址如下,欢迎 fork+star 鼓励一下老马~
sensitive-word
java 实现
词库准备
敏感词库就是一行行敏感词,比如【黄色】
虽然说这个词可能是中性的,但是我们只是举一个比较和谐的例子。
流程梳理
我们根据上面的图,可以将状态图整理如下:
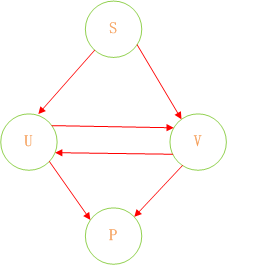
同时这里没有状态转换,没有动作,有的只是Query(查找)。
我们可以认为,通过S query U、V,通过U query V、P,通过V query U P。
通过这样的转变我们可以将状态的转换转变为使用Java集合的查找。
例子
诚然,加入在我们的敏感词库中存在如下几个敏感词:日本人、日本鬼子。
那么我需要构建成一个什么样的结构呢?
首先:
query 日 ---> {本}、query 本 --->{人、鬼子}、query 人 --->{null}、query 鬼 ---> {子}
形如下结构:
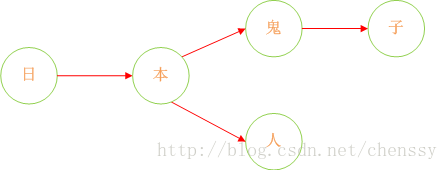
这样我们就将我们的敏感词库构建成了一个类似与一颗一颗的树,这样我们判断一个词是否为敏感词时就大大减少了检索的匹配范围。比如我们要判断日本人,根据第一个字我们就可以确认需要检索的是那棵树,然后再在这棵树中进行检索。
如何判断结束
但是如何来判断一个敏感词已经结束了呢?
利用标识位来判断。
所以对于这个关键是如何来构建一棵棵这样的敏感词树。
具体流程
下面我已Java中的HashMap为例来实现DFA算法。
具体过程如下:
日本人,日本鬼子为例
1、在hashMap中查询“日”看其是否在hashMap中存在,如果不存在,则证明已“日”开头的敏感词还不存在,则我们直接构建这样的一棵树。跳至3。
2、如果在hashMap中查找到了,表明存在以“日”开头的敏感词,设置hashMap = hashMap.get(“日”),跳至1,依次匹配“本”、“人”。
3、判断该字是否为该词中的最后一个字。若是表示敏感词结束,设置标志位 isEnd = 1,否则设置标志位 isEnd = 0;

java 程序实现
DFA 树的初始化
@SuppressWarnings("unchecked")
word">public word">void initWordMap(Collection<String> collection) {
// 避免重复加载
word">if (MapUtil.isNotEmpty(innerWordMap)) {
word">return;
}
word">long startTime = System.currentTimeMillis();
// 避免扩容带来的消耗
innerWordMap = word">new HashMap(collection.size());
word">for (String key : collection) {
word">if (StringUtil.isEmpty(key)) {
word">continue;
}
// 用来按照相应的格式保存敏感词库数据
word">char[] chars = key.toCharArray();
word">final word">int size = chars.length;
// 每一个新词的循环,直接将结果设置为当前 map,所有变化都会体现在结果的 map 中
Map currentMap = innerWordMap;
word">for (word">int i = 0; i < size; i++) {
// 截取敏感词当中的字,在敏感词库中字为HashMap对象的Key键值
word">char charKey = chars[i];
// 如果集合存在
Object wordMap = currentMap.get(charKey);
// 如果集合存在
word">if (ObjectUtil.isNotNull(wordMap)) {
// 直接将获取到的 map 当前当前 map 进行继续的操作
currentMap = (Map) wordMap;
} word">else {
//不存在则,则构建一个新的map,同时将isEnd设置为0,因为他不是最后一
Map<String, Boolean> newWordMap = word">new HashMap<>(8);
newWordMap.put(AppConst.IS_END, false);
// 将新的节点放入当前 map 中
currentMap.put(charKey, newWordMap);
// 将新节点设置为当前节点,方便下一次节点的循环。
currentMap = newWordMap;
}
// 判断是否为最后一个,添加是否结束的标识。
word">if (i == size - 1) {
currentMap.put(AppConst.IS_END, true);
}
}
}
word">long endTime = System.currentTimeMillis();
System.out.println("Init sensitive word map end! Cost time: " + (endTime - startTime) + "ms");
}
DFA 树的使用
/**
* 检查敏感词
* <p>
* (1)如果未命中敏感词,直接返回 0
* (2)命中敏感词,则返回敏感词的长度。
*
* ps: 这里结果进行优化,
* 1. 是否包含敏感词。
* 2. 敏感词的长度
* 3. 正常走过字段的长度(便于后期替换优化,避免不必要的循环重复)
*
* @param txt 文本信息
* @param beginIndex 开始下标
* @param validModeEnum 验证模式
* @param context 执行上下文
* @return 敏感词对应的长度
* @since 0.0.1
*/
word">private word">int checkSensitiveWord(word">final String txt, word">final word">int beginIndex,
word">final ValidModeEnum validModeEnum,
word">final IWordContext context) {
Map nowMap = innerWordMap;
// 记录敏感词的长度
word">int lengthCount = 0;
word">int actualLength = 0;
word">for (word">int i = beginIndex; i < txt.length(); i++) {
word">char c = txt.charAt(i);
word">char charKey = getActualChar(c, context);
// 判断该字是否存在于敏感词库中
// 并且将 nowMap 替换为新的 map,进入下一层的循环。
nowMap = (Map) nowMap.get(charKey);
word">if (ObjectUtil.isNotNull(nowMap)) {
lengthCount++;
// 判断是否是敏感词的结尾字,如果是结尾字则判断是否继续检测
word">boolean isEnd = (word">boolean) nowMap.get(AppConst.IS_END);
word">if (isEnd) {
// 只在匹配到结束的时候才记录长度,避免不完全匹配导致的问题。
// eg: 敏感词 敏感词xxx
// 如果是 【敏感词x】也会被匹配。
actualLength = lengthCount;
// 这里确实需要一种验证模式,主要是为了最大匹配从而达到最佳匹配的效果。
word">if (ValidModeEnum.FAIL_FAST.equals(validModeEnum)) {
word">break;
}
}
} word">else {
// 直接跳出循环
word">break;
}
}
word">return actualLength;
}
DFA 算法的思考
虽说性能上没有任何问题。
但是 DFA 有一个缺点,那就是占用的内存和敏感词字典的大小成正比。
开源框架
参考 sensitive-word
参考资料
Java实现敏感词过滤
使用 DFA 实现文字过滤
java实现敏感词过滤(DFA算法)