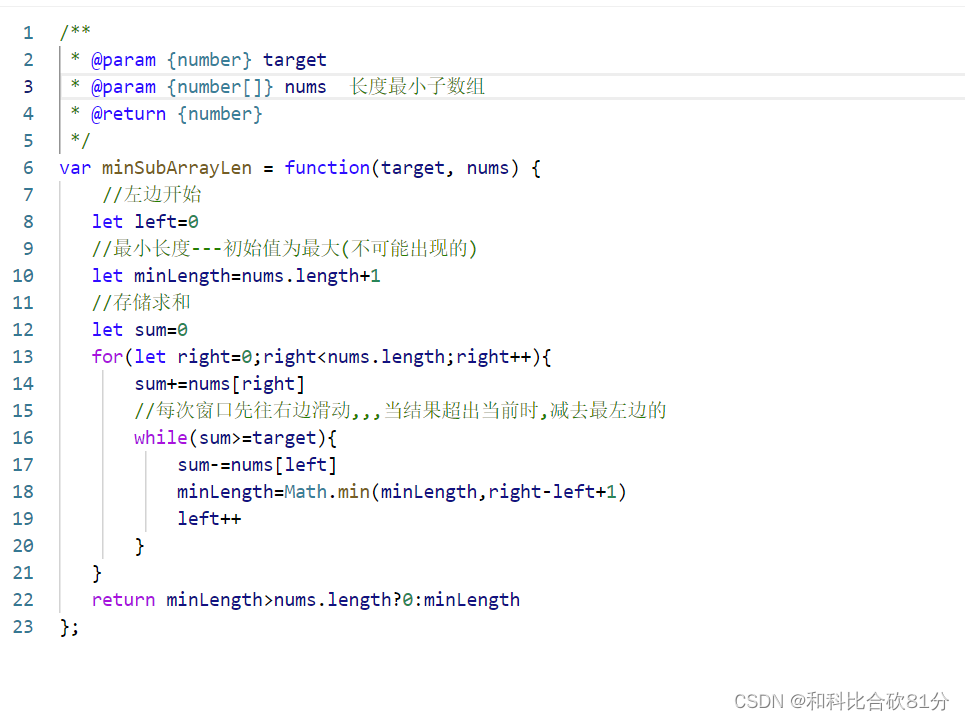
DS简介:
DolphinScheduler 是一款分布式的、易扩展的、高可用的数据处理平台,主要包含调度中心、元数据管理、任务编排、任务调度、任务执行和告警等模块。其技术架构基于 Spring Boot 和 Spring Cloud 技术栈,采用了分布式锁、分布式任务队列等技术确保任务高可用性。部署灵活,支持单机部署、分布式部署、容器化部署等方式。应用场景广泛,可用于大数据处理、定时任务和流程管理等领域。具有易扩展性、高可用性、多语言支持、易用性和活跃的开发社区等技术优势。支持二次开发和插件机制,可以与其他大数据处理框架无缝集成。已被阿里巴巴、腾讯、美团、京东等大型互联网公司广泛使用,市场前景广阔,未来发展可期。可为BI和AI应用提供数据支持。
一、系统架构

DolphinScheduler 是一款分布式的、易扩展的、高可用的数据处理平台。它主要包含了调度中心、元数据管理、任务编排、任务调度、任务执行和告警等模块。
其中,调度中心是 DolphinScheduler 的核心模块,提供了用户操作界面,支持 DAG 编排任务,同时也是任务调度的控制中心,负责任务的调度、监控和告警。元数据管理模块是 DolphinScheduler 的元数据存储引擎,负责存储和管理任务的元数据信息,以及提供元数据查询 API 接口。
任务编排模块提供了 DAG 图编辑器,支持图形化的 DAG 编排,让任务编排更加直观。
任务调度模块是 DolphinScheduler 的核心模块,负责任务的调度,同时也支持手动调度和定时调度。
任务执行模块是负责执行任务的模块,支持多种不同的任务类型,包括 Hadoop、Spark、Flink 等大数据处理框架。
告警模块是 DolphinScheduler 支持的一个重要特性,可以在任务出现异常或者发生故障时进行告警。
二、技术架构

DolphinScheduler 的技术架构主要由以下几个模块组成:
-
Master Server(调度中心): Master Server 是 DolphinScheduler 的核心模块,负责整个系统的调度和控制。它管理任务的调度逻辑,监控任务的执行情况,并负责任务的告警和监控。Master Server 采用分布式架构,能够实现横向扩展,保证了系统的高可用性和可靠性。
-
ZooKeeper(元数据管理): DolphinScheduler 使用 ZooKeeper 作为元数据管理模块,用于存储和管理任务的元数据信息,以及提供元数据查询 API 接口。ZooKeeper 提供了分布式协调服务,用于实现分布式锁、选举等功能,保证了系统的一致性和可靠性。
-
API Server(任务编排与调度): API Server 提供了任务编排和任务调度的接口服务,用户可以通过 API Server 提供的接口进行 DAG 编排、任务调度等操作。API Server 还负责将用户提交的任务请求转发给 Master Server 进行处理,并返回执行结果给用户。
-
Alert Server(告警模块): Alert Server 负责系统告警功能,当任务出现异常或者发生故障时,Alert Server 会发送告警通知给相关人员或系统,以便及时处理。
-
Worker Server(任务执行): Worker Server 负责执行任务的模块,支持多种不同的任务类型,包括 Hadoop、Spark、Flink 等大数据处理框架。Worker Server 接收来自 Master Server 的任务调度请求,执行具体的任务逻辑,并将执行结果返回给 Master Server。
这些模块共同组成了 DolphinScheduler 的技术架构,实现了任务的调度、编排、执行和监控,保证了系统的高可用性和可靠性。
DolphinScheduler 的技术架构采用了分布式架构,基于 Spring Boot 和 Spring Cloud 技术栈构建而成,同时还采用了一些开源技术,包括 ZooKeeper、MySQL、Redis、Elasticsearch 等。DolphinScheduler 使用了分布式锁、分布式任务队列等技术,保证了任务的高可用性和可靠性。
DolphinScheduler 还支持多种数据源,包括 MySQL、Oracle、PostgreSQL 等关系型数据库,以及 Hadoop、Hive、Spark、Flink 等大数据处理框架。
三、部署架构
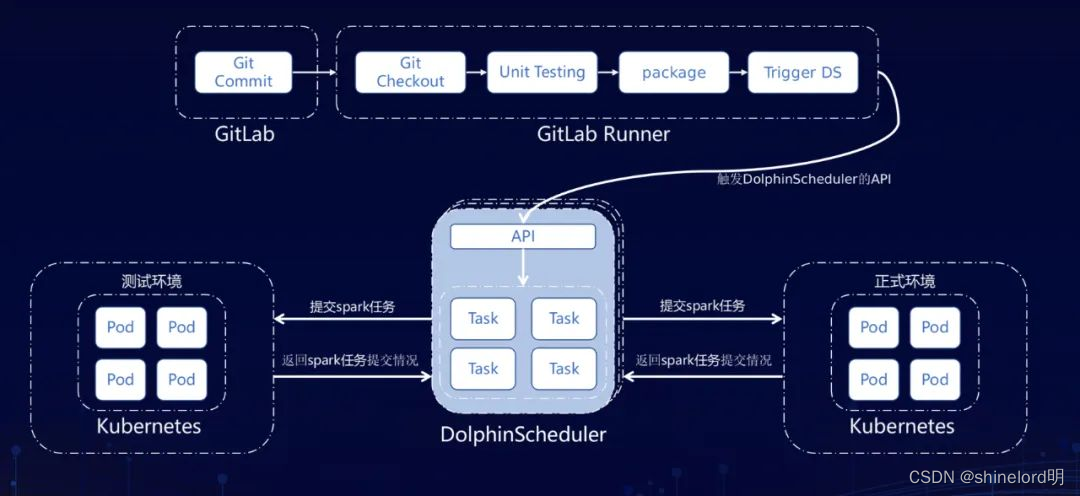
DolphinScheduler 的部署架构非常灵活,支持单机部署、分布式部署、容器化部署等多种方式。在单机部署中,可以通过 Docker 镜像或者二进制包的方式进行部署;在分布式部署中,可以通过 Kubernetes 或者 Mesos 等容器编排技术进行部署。
四、应用场景
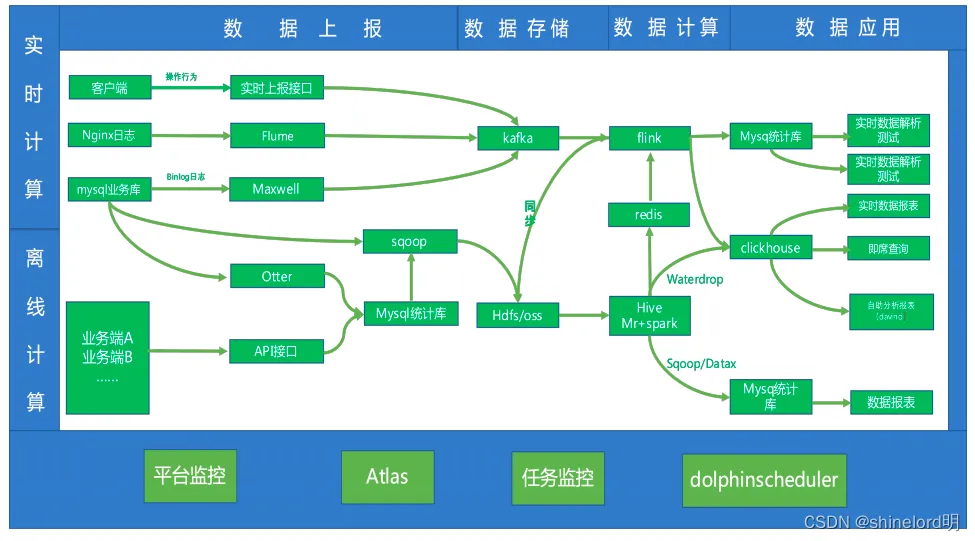
DolphinScheduler 主要应用于大数据处理领域,可以支持 Hadoop、Hive、Spark、Flink 等多种数据处理框架。它可以帮助企业实现数据处理的自动化,并提高数据处理的效率和准确性。除此之外,DolphinScheduler 还可以应用于各种定时任务和流程管理。
五、技术优势
DolphinScheduler 具有以下几个技术优势:
-
易扩展性:DolphinScheduler 的分布式架构可以轻松实现扩展,根据实际业务需求进行灵活配置。
-
高可用性:DolphinScheduler 采用了分布式锁、分布式任务队列等技术,保证了任务的高可用性和可靠性。
-
多语言支持:DolphinScheduler 支持多种编程语言,包括 Java、Python、Scala 等,可以方便地集成到不同的应用场景中。
-
易用性:DolphinScheduler 提供了友好的 Web UI 用户界面,支持图形化的 DAG 编排,让任务编排更加直观。
-
社区活跃度:DolphinScheduler 的开发团队十分活跃,社区贡献者众多,社区版本更新迅速,能够及时解决用户反馈的问题,并提供新的功能特性。
六、功能模块
DolphinScheduler 主要包含以下功能模块:
-
调度中心:提供了用户操作界面,支持 DAG 编排任务,是任务调度的控制中心,负责任务的调度、监控和告警。
-
元数据管理:存储和管理任务的元数据信息,提供元数据查询 API 接口。
-
任务编排:提供了 DAG 图编辑器,支持图形化的 DAG 编排,让任务编排更加直观。
-
任务调度:负责任务的调度,同时也支持手动调度和定时调度。
-
任务执行:负责执行任务的模块,支持多种不同的任务类型,包括 Hadoop、Spark、Flink 等大数据处理框架。
-
告警模块:在任务出现异常或者发生故障时进行告警。
七、部署方式
DolphinScheduler 的部署方式包括以下几种:
-
单机部署:可以通过 Docker 镜像或者二进制包的方式进行部署。
-
分布式部署:可以通过 Kubernetes 或者 Mesos 等容器编排技术进行部署。
-
容器化部署:支持 Docker 容器化部署,方便快捷。
八、二次开发
DolphinScheduler 支持二次开发,用户可以根据自己的业务需求进行扩展和定制。DolphinScheduler 提供了完善的开发文档和 API 接口,方便用户进行二次开发。此外,DolphinScheduler 还提供了插件机制,用户可以根据自己的需求自定义插件,并且方便地集成到 DolphinScheduler 中。
九、集成方式
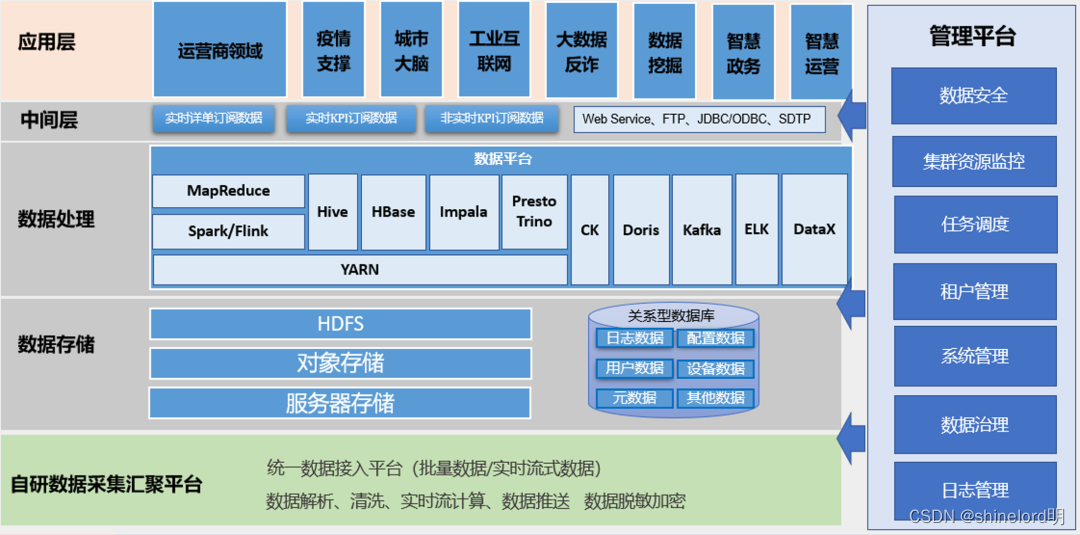
DolphinScheduler 支持多种集成方式,可以与其他大数据处理框架进行无缝集成。例如,可以与 Hadoop、Hive、Spark、Flink 等数据处理框架进行集成,实现数据的自动化处理和调度。
十、社区活跃度
DolphinScheduler 的开发团队十分活跃,社区贡献者众多,社区版本更新迅速,能够及时解决用户反馈的问题,并提供新的功能特性。此外,DolphinScheduler 还有一个非常活跃的社区,用户可以在社区中交流经验、分享资源、解决问题。
十一、哪些大公司在使用

DolphinScheduler 目前已经得到了国内外很多大型互联网公司的广泛应用,包括阿里巴巴、腾讯、美团、京东、滴滴等。
十二、市场前景
随着大数据技术的不断发展,企业对于数据处理的需求也越来越高。DolphinScheduler 作为一款分布式的、易扩展的、高可用的数据处理平台,具备很强的市场竞争力。据市场研究机构预测,未来几年大数据处理领域的市场规模将会持续扩大,DolphinScheduler 有望成为该领域的重要参与者。
十三、未来发展
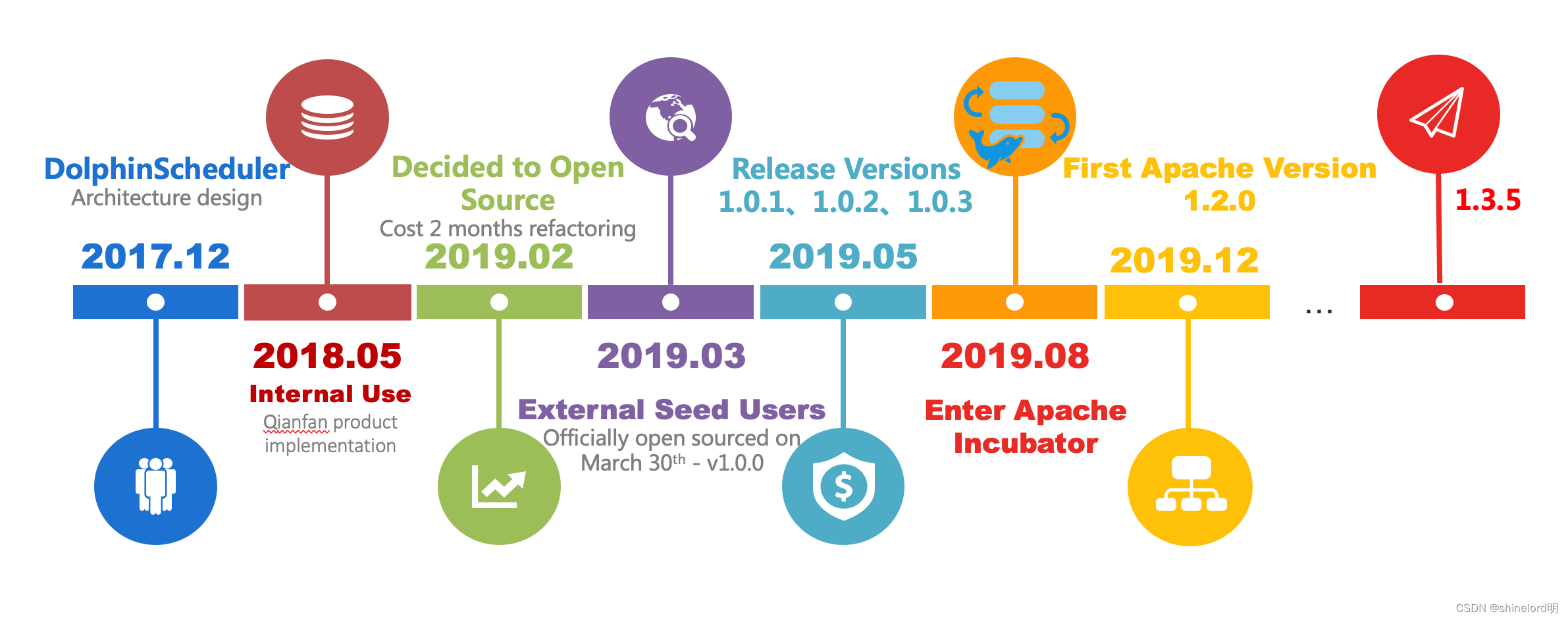
未来,DolphinScheduler 将继续保持活跃的开发态势,不断增加新的功能特性,提高系统的稳定性和可靠性。同时,DolphinScheduler 还将继续推进对更多数据处理框架的支持,以及更加灵活的部署方式和集成方式,为用户提供更加优秀的产品体验。
十四、BI与AI应用
DolphinScheduler 可以作为大数据处理平台的一部分,为 BI(商业智能)和 AI(人工智能)应用提供支持。通过 DolphinScheduler,企业可以将数据处理自动化,提高数据处理效率,进而为 BI 和 AI 应用提供更加准确、可靠的数据支持。