转载请注明出处:http://blog.csdn.net/u012842205/article/details/73290278
Druid是一个高性能的面向列存储的分布式存储系统。支持亚秒级的点对点数据查询,包括数据分组,聚合,过滤等操作。其实现目标是支持面向应用的多用户交互查询。可以接入实时数据流(如Kafka)或载入静态数据文件,事先完成数据预计算,以提供更快的查询性能。Druid部署硬件要求较高,主要是内存上的要求,因大部分数据都会载入内存,同时Druid又是一个内存数据库。本文主要介绍Druid安装部署。
一、安装环境
操作系统:Ubuntu 16.04 LTS
Zookeeper:Apache Zookeeper 3.4.8(三个节点:vdebianez3:2181,vubuntuez1:2181,vcentosez2:2181)
Druid:0.10.0
主机名称:vubuntuez1
运行用户:druid
JDK:Oracle JDK 1.8.0_101(这个最好是1.8以上版本)
二、下载解压
从官网下载Druid部署包,下载地址:http://static.druid.io/artifacts/releases/druid-0.10.0-bin.tar.gz。
解压到/home/druid:
tar -xzvf ./druid-0.10.0-bin.tar.gz -C /home/druid简单说说conf目录的结构。
./conf
├── druid
│ ├── broker
│ │ ├── jvm.config
│ │ └── runtime.properties
│ ├── _common
│ │ ├── common.runtime.properties
│ │ └── log4j2.xml
│ ├── coordinator
│ │ ├── jvm.config
│ │ └── runtime.properties
│ ├── historical
│ │ ├── jvm.config
│ │ └── runtime.properties
│ ├── middleManager
│ │ ├── jvm.config
│ │ └── runtime.properties
│ └── overlord
│ ├── jvm.config
│ └── runtime.properties
└── tranquility
├── kafka.json
└── server.json
这里主要是看druid子目录,其中放置了各种节点的配置文件,相互之间不干扰,但还有一个存放公共配置文件的位置,在conf/druid/_common/下。比如,当我们需要配置coordinator节点时,配置conf/druid/coordinator/下的文件即可。
另外,有一个quickstart_conf/目录和conf/目录结构基本一致,这个是配置伪分布式节点的目录,本文主要的配置文件都在这个地方。
三、配置
本文将配置所有的节点(broker、overload、middleManager、historical、coordinator各一个)到一台服务器上,并启动,其中依赖的zookeeper服务事先已经配置好。修改conf-quickstart/druid/_common/common.runtime.properties:
druid.zk.service.host=vubuntuez1:9092,vdebianez3:9092,vcentosez3:9092
druid.zk.paths.base=/druid_quickstart
Druid会需要一个RDBMS作为元数据存储,这里我们只是用内嵌的Derby数据库,全使用默认配置即可。后一篇分布式部署我们将使用MySQL数据库作为元数据存储。
这样配置完成后,数据将存储在Druid部署根目录的var/下。
四、启动服务
启动所有配置前先运行部署根目录的如下脚本:
bin/init这个脚本主要是创建var/路径,并产生模拟数据文件,供后面我们载入数据测试。
现在运行五个节点服务(全在这个节点运行),写成脚本如下:
#!/bin/bash
ROOT=`dirname $0`
LOG_DIR=$ROOT/quickstart_log
nohup java `cat conf-quickstart/druid/historical/jvm.config | xargs` -cp "conf-quickstart/druid/_common:conf-quickstart/druid/historical:lib/*" io.druid.cli.Main server historical >> $LOG_DIR/historical.log 2>&1 &
nohup java `cat conf-quickstart/druid/broker/jvm.config | xargs` -cp "conf-quickstart/druid/_common:conf-quickstart/druid/broker:lib/*" io.druid.cli.Main server broker >> $LOG_DIR/broker.log 2>&1 &
nohup java `cat conf-quickstart/druid/coordinator/jvm.config | xargs` -cp "conf-quickstart/druid/_common:conf-quickstart/druid/coordinator:lib/*" io.druid.cli.Main server coordinator >> $LOG_DIR/coordinator.log 2>&1 &
nohup java `cat conf-quickstart/druid/overlord/jvm.config | xargs` -cp "conf-quickstart/druid/_common:conf-quickstart/druid/overlord:lib/*" io.druid.cli.Main server overlord >> $LOG_DIR/overlord.log 2>&1 &
nohup java `cat conf-quickstart/druid/middleManager/jvm.config | xargs` -cp "conf-quickstart/druid/_common:conf-quickstart/druid/middleManager:lib/*" io.druid.cli.Main server middleManager >> $LOG_DIR/middleManager.log 2>&1 &我们全部使用nohup切换成Linux daemon进程。重定向输出文件到部署根目录的quickstart_log。这个目录请自行手动创建。
检查没问题后运行这个脚本,查看日志,确保运行稳定不抛出异常。可以尝试用浏览器访问前端网页:
http://vubuntuez1:8081/
http://vubuntuez1:8090/
五、数据载入
现在我们尝试将数据导入Druid,成为一个Druid系统的数据源,供测试使用。Druid接受多种数据接入形式,比如Kafka数据流,HTTP REST接口定期拉取,静态文件导入。本文目前使用最简单的静态数据文件导入。
静态文件格式也支持很多,我们尝试CSV和JSON两种格式。Druid也支持外部数据格式扩展,自己实现序列化反序列化,供Druid调用。
1、自定义CSV文件
数据文件device_datas.dat如下:
YY,1496284771001,3.855
FI,1496284771001,2.436
RY,1496284771001,2.024
HB,1496284771002,4.294
PN,1496284771003,1.997
PV,1496284771003,3.604
接着我们编写作业JSON,一般称为Spec文件,这个文件用于传输给Druid系统,告诉Druid需要执行加载作业的详细信息,包括数据文件位置,数据如何解析,统计指标定义等。编写好后将通过REST请求提交给overload服务,调动整个集群组件完成数据加载服务。如下是我们的Spec文件,test_index.json。
{
"type" : "index_hadoop",
"spec" : {
"ioConfig" : {
"type" : "hadoop",
"inputSpec" : {
"type" : "static",
"paths" : "quickstart/device_datas.dat"
}
},
"dataSchema" : {
"dataSource" : "test_datas",
"granularitySpec" : {
"type" : "uniform",
"segmentGranularity" : "day",
"queryGranularity" : "none",
"intervals" : ["2017-06-01/2017-06-02"]
},
"parser":{
"type":"hadoopyString",
"parseSpec":{
"format":"csv",
"columns":["dev_name","tm","f1"],
"dimensionsSpec":{
"dimensions" : [
"dev_name"
]
},
"timestampSpec" : {
"format" : "millis",
"column" : "tm"
}
}
},
"metricsSpec" : [
{
"name" : "count",
"type" : "count"
},
{
"name":"sumf1",
"type":"doubleSum",
"fieldName":"f1"
}
]
},
"tuningConfig" : {
"type" : "hadoop",
"partitionsSpec" : {
"type" : "hashed",
"targetPartitionSize" : 5000000
},
"jobProperties" : {}
}
}
}(1)spec.ioConfig.inputSpec
这个键对应的值是个JSON对象,两个字段:type,表示数据IO的类型,这里是静态数据文件,我们设置为static;path,这个字段非常好理解,数据文件名称就是。根目录默认是Druid根目录。
(2)spec.dataSchema.dataSource
这个键对应的是字符串,是数据源的名称,数据文件加载到Druid系统,会使用一个数据源名称来标示,标示这块数据,起一个名字即可。
(3)spec.dataSchema.granularitySpec
设置统计数据的时间范围和粒度,也就是指定统计某个时间段的数据,intervals我们设置成"2017-06-01/2017-06-02",即是统计这个时间段内的数据。segmentGranularity设置成天。
(4)spec.dataSchema.parser
这个键对应的是对象,比较复杂,也是最需要注意的。先配置type,一般文本文件都配置成String或者hadoopString。接下来是parseSpec:
format是数据文件的存储格式,我们的数据文件是JSON。
columns,这里按顺序列举出CSV文件的各个列的列名。我们的列名是dev_name,tm(时间戳),f1(数据列)。
dimensionsSpec指定维度列,一般维度列都是些可以枚举出的常量列,比如城市,比如地区编码,比如设备编码,统计可以根据这些列作不同维度的上卷,下钻等操作。我们的维度只有第一列,dev_name。
timestampSpec,指定时间戳列,我们的时间列是第二列,列名tm,格式是Unix时间戳,单位是毫秒。
(5)spec.dataSchema.metricsSpec
这个键用于定义统计指标,上文已经说明了,统计指标是两个,count和sum,一个指标一个JSON对象,第一个对象不用指定数据列,name是count,聚合操作type是count;
第二个统计指标是sum,统计列fieldName是f1,统计类型type是doubleSum,名称是sumf1。
改好后,提交给overlord节点,我们使用HTTP REST推送过去,使用curl工具即可。
数据文件和Spec文件放置在Druid部署根目录的quickstart/下,在Druid部署根目录运行如下命令:
curl -X 'POST' -H 'Content-Type:application/json' -d @./test_index.json localhost:8090/druid/indexer/v1/task若返回如下JSON则提交成功:
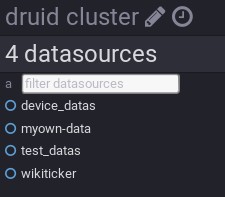
{"task":"index_hadoop_test_datas_2017-06-15T08:53:09.076Z"}接下来可以查看前端UI页面,直到运行结束,如下图,可以看到数据已经加载成功,也出现了test_datas数据源:
http://vubuntuez1:8090/

http://vubuntuez1:8081
2、自定义JSON文件
下一篇讲Druid分布式部署。
